In the spring of 2020 my research work on Reinforcement Learning with Sparse Binary Rewards done with my brilliant collaborator Minah Seo was featured in the KAIST Breakthroughs webzine. In the paper, we try to tackle the challenge of training robots with reinforcement learning in settings in which the reinforcement signal (reward) is infrequent and delayed, not appearing immediately after the action that triggered the reward. For example, it can take thousands of actions for the robot to solve a Rubik’s cube. Because of the long delay to receive feedback, the robot is not able to recognize which actions were the important ones leading to success.
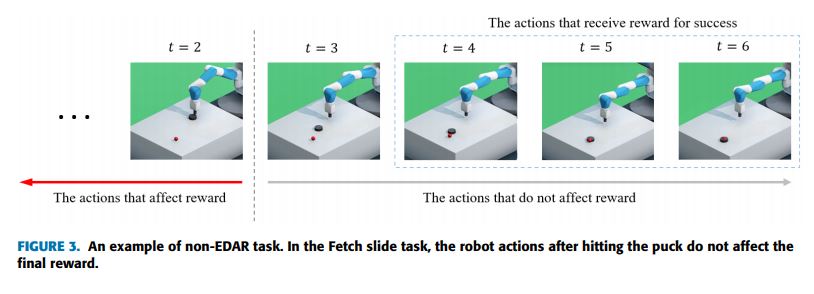
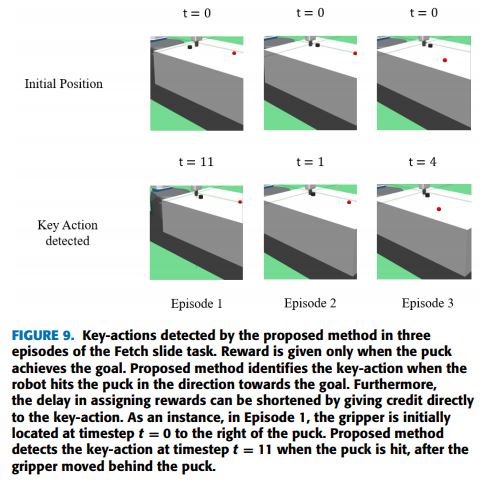
To solve this problem we proposed a method to detect the most important action contributing to the accomplishment of a task by a robot arm. This action is defined as the key action leading the robot to success. The key action is detected based on a neural network model that tries to predict future outcomes in the system, such as the probability of accomplishing a task. With the result of the detection, positive feedback is then re-assigned to the key actions during the training of the deep reinforcement learning algorithm. The results of the experiments realized with a robotic arm simulator have shown that the assignment of feedback directly to the important actions improved the performance, reducing the number of failures, and affected the behavior of the robot. At that moment, we interpolated and mentioned that the results indicated that an important factor for the development of future robotic systems, such as humanoid robots, using deep learning, especially deep reinforcement learning, was the ability to predict future outcomes based on its current actions.
If you are interested in reading the full paper, the work is published in the IEEE Access open access journal in this link.
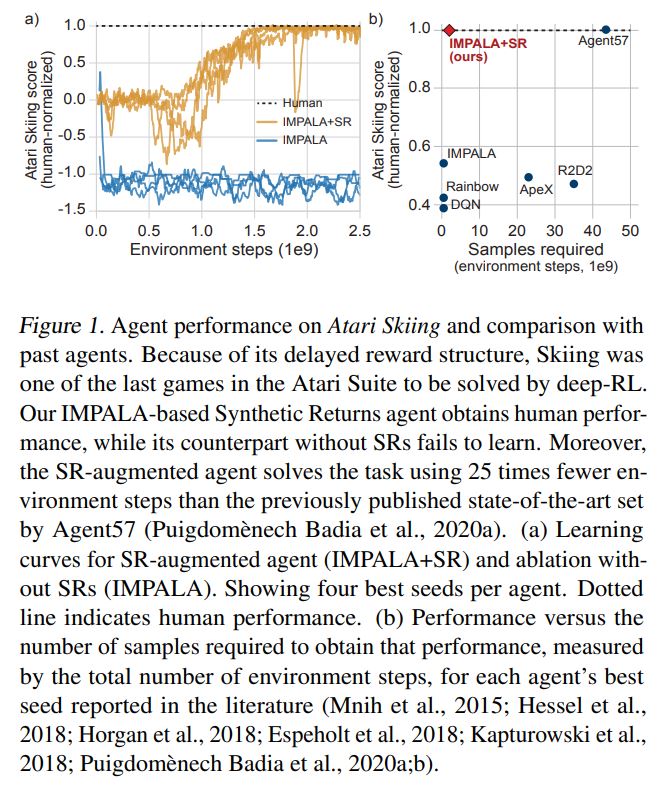
In parallel to our work, other researchers, such as [1-3] tackled the problem of credit assignment with delayed rewards. However, when this week Google Deepmind released a paper named “Synthetic Returns for Long-Term Credit Assignment” [4] by David Raposo and Sam Ritter applying an idea really similar to our proposed model, it was very exciting to see their work achieving state-of-the-art results in the Atari Skiing environment and in other toy environments with delayed rewards.
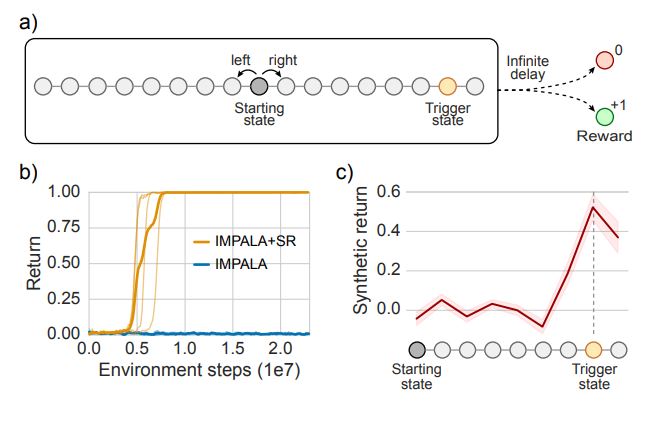
In the paper they propose what is called state associative (SA) learning, where the agent learns associations between states and arbitrarily distant future rewards, then re-assigns credit accordingly between the two. With the model it is possible predict each state’s contribution to the far future, a quantity called “synthetic returns”. Therefore, they use the state information to make predictions of future rewards received. In our work, on the other hand, we use both the state and actions to make these predictions. They also highlight that the learned synthetic returns are interpretable, meaning that they have higher values for states that occur after critical actions are taken. In our case, our model demonstrated also to be interpretable by recognizing what we defined as key-actions that are the most important actions leading to the reward received in the future.
Comparing with the other related work in the area, the most important of the paper might be the loss function introduced to train their rewards prediction model, that is also a neural network. Quoted from their paper: “The new network is trained to output the reward for each timestep t given the state representations {s0, …, st} in the augmented agent state.”. The loss function can be seen next. The main point is the presence of b(s) and c(s) that are two regressors that try to predict future rewards regardless of how far on the future that reward occurs. That is a main difference from our proposed model that predicts the future rewards for a fixed number of timesteps defined by the researcher. The full explanation of the loss function and the details of their model can be seen in the arxiv link.
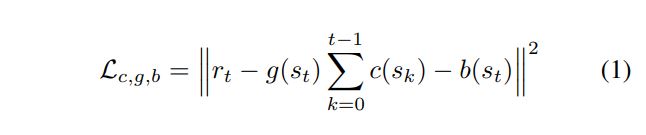
The results obtained training a rewards prediction model to teach the agent important states and actions leading to rewards received in the future have shown that it might be a tendency to have agents capable of more understanding of the environment he is inserted. In recent years, we have seen model-free reinforcement learning combined with tree-based planning methods achieving breakthrough state-of-the-art results in deterministic and video game environments. Usually, for that kind of environment, model-based methods were hard to train and did not achieve good results. However, after DeepMind (again!) was able to obtain state-of-the-art results to master Atari, Go, chess and shogi [5] by using an algorithm that was able to model the dynamics of these games and also contained the ability to predict future rewards the area is changing. In summary, I expect big advances in model-based reinforcement learning in the following years achieving breakthrough results in environments with complex dynamics, such as robotic environments, and with interpretable models that will help us understanding the reasoning behind the decision taken by the agents at each moment.
REFERENCES
[1] Ferret, J., Marinier, R., Geist, M., and Pietquin, O. Selfattentional credit assignment for transfer in reinforcement learning. arXiv preprint arXiv:1907.08027, 2019.
[2] Harutyunyan, A., Dabney, W., Mesnard, T., Azar, M., Piot, B., Heess, N., van Hasselt, H., Wayne, G., Singh, S., Precup, D., et al. Hindsight credit assignment. arXiv preprint arXiv:1912.02503, 2019.
[3] Arjona-Medina, J. A., Gillhofer, M., Widrich, M., Unterthiner, T., Brandstetter, J., and Hochreiter, S. Rudder: Return decomposition for delayed rewards. arXiv preprint arXiv:1806.07857, 2018.
[4] Raposo, David, et al. “Synthetic Returns for Long-Term Credit Assignment.” arXiv preprint arXiv:2102.12425 (2021).
[5] Schrittwieser, Julian, et al. “Mastering atari, go, chess and shogi by planning with a learned model.” Nature 588.7839 (2020): 604-609.