In 2015, when I was starting my Master’s I remember being fascinated by the introduction to Recurrent Neural Networks (RNNs) and Long-short Term Memories (LSTM) that I read in Chris Olah’s blog. Not only the writing and details were so clear written by Chris but the potential of these networks got my attention. I decided to research further on how that could be applied to my research in NLP algorithms for Speech Synthesis at that moment. Naturally, I read Ilya Sutskever paper on Sequence to Sequence Learning with Neural Networks that, at that moment, achieved amazing results in language translation. After I read the paper I realized that the Seq-to-Seq architecture could be applied in many different applications due to its flexibility in modeling.
For my research in Speech Synthesis, most of the algorithms I used for the NLP part in Brazilian Portuguese (BP) were rule-based approaches. So, I decided to research and evaluate how these Seq-to-Seq models and data-driven approaches would compare to the problems I tackled in a Text-to-Speech system. So, at that time, I proposed as a novel application, the use of Sequence-to-Sequence models as solution for the Grapheme-to-Phoneme (G2P) conversion, Syllabification and Stress Determination problems in TTS systems. Parallel to that, Daan van Esch was also doing an amazing work on the same area that you can check here. And, as a joint result, we both have shown that data-driven algorithms can achieve state-of-the-art performance for the NLP algorithms presented in the Text Analysis block of a TTS system.
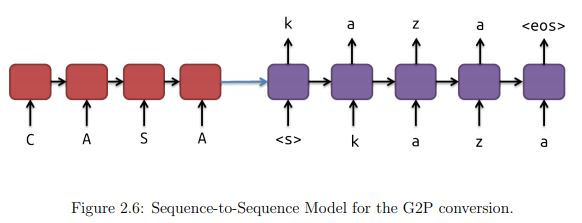
So, after this quick introduction, let’s get into the basic models that are really simple. The input is read one character at a time until its end to form the fixed-dimensional vector. The output RNN is used to decode the phoneme sequence from this vector. This model is showed in the next figure for the conversion of the word “casa” (house). Next, each block is a LSTM model. In the figure just one layer is presented, but the architecture also works with 2 or more layers as a deep LSTM. During the model implementation, the input word is reversed to introduce more short term dependencies. Thus, the word “casa” would be inserted in the model as “asac”. The target sequence keeps the same order.
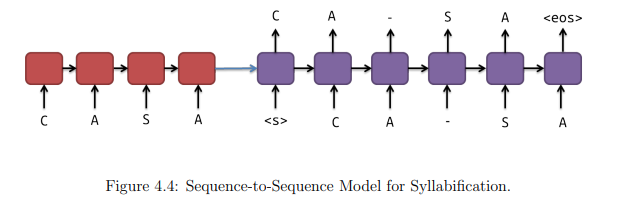
Next, we proposed at that time tackling the Syllabification task using Sequence-toSequence Models. So, the model for this task can be interpreted as a mapping sequence problem. To do this we will keep using the word as the input, inserted one character at a time. Remind that the word is inserted in reverse order. The modifications are related to the mapping on the output side of the model. The output chosen is the word with the syllable boundaries in the right position. The syllable boundaries are represented by an extra character. In our case, we chose the character “-”, but any character outside the alphabet symbols for the target language can be used. The model used for training can be seen in the next figure.
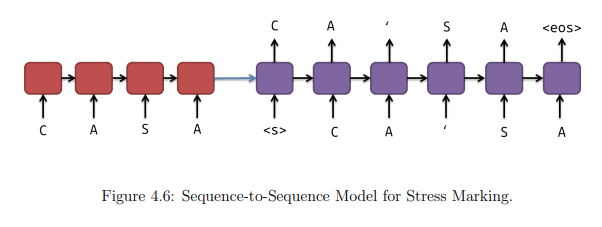
The same idea of turning the structured classification problem into a mapping sequence problem used for Syllabification is also used for Stress Determination. The idea now is to identify the existence of stress markers between graphemes. To do this we will keep using the unmodified word as input. One more time, the modifications are made in the decoding side of the model. The output chosen is the word with the stress markers in their right position. The stress marker is represented by the character “’”. As in the Syllabification task presented, the problem can be seen as predicting the next character generated, where the prediction of the character “’” indicates the presence of stress. The model used for training can be seen in the next figure.
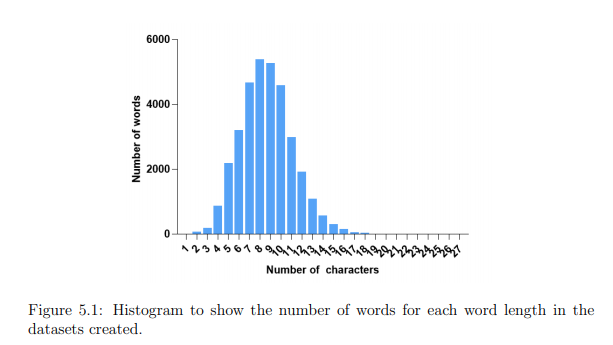
The lack of open source standardized datasets for BP was a problem at that time. So, in order to perform the experiments three datasets for Brazilian Portuguese were created. One for G2P conversion, one for Syllabification and one for Stress Determination. First of all, to develop the datasets, a list of all the words contained in the Ispell Dictionary was created. In this list, some foreign language material and words that contained simple orthographic errors were discarded. The final version of the list then contained 33737 words. This is also the length of the datasets created. A histogram that shows the length of the lexicon words is presented next.
We report results for the rule-based and data-driven approaches for G2P conversion in the next figure. The first conclusion that can be taken from the table is the ability of the data-driven approaches to yield similar or outperform the G2P rule-based algorithm. The three data-driven algorithms chosen were able to present better Phoneme Error Rate than the rule-based algorithm, with the Sequence-toSequence Models achieving the best rate overall with PER equal to 0.52 ± 0.05%. These results can also be seen in Figure 5.2. For the Word Error Rate, the rule-based algorithm showed better results than two data-driven algorithms, but was outperformed by Sequence-to-Sequence Models that presented WER equal to 2.28±0.13%.
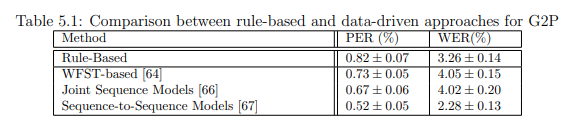
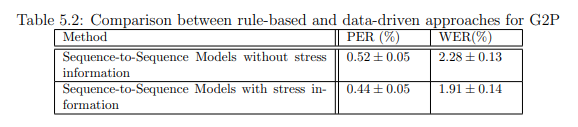
And we also realized that including the stress information in the input part of the Seq-to-Seq model could improve the results as shown next.
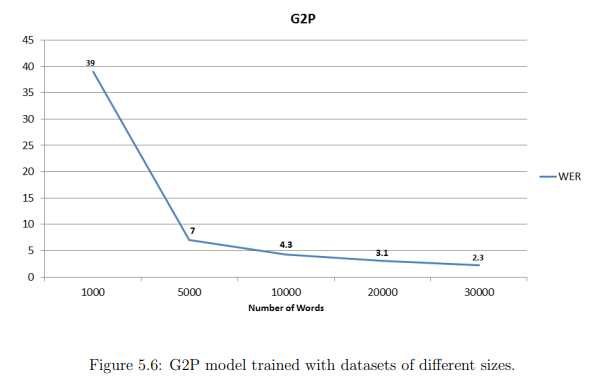
Next, we also show the influence of the size of the dataset in the results obtained by the Seq-to-Seq model for G2P.
The results obtained for the syllabification problem can be seen next. First of all, we should explain that for this experiment just WER is used as a performance metric because the PER using Levenshtein distance has no meaning for the proposed model. For this model, a new performance metric regarding the right positioning of the syllable boundaries should be proposed and implemented. So, analyzing the results we can see that the proposed model clearly outperforms the rule-based algorithm. The proposed Sequence-to-Sequence Model achieve a WER of 1.70 ± 0.32% against 4.15 ± 0.18% from the rule-based algorithm.

The results obtained for the stress marking problem can be seen next. It is important to mention the presence of accent markers in BP to highlight stress patterns. Therefore, rule-based algorithms perform really well for this task. As the dataset was created by the author manually correcting the output generated by the rule-based algorithm, the author consider the dataset being representative of the rule-based algorithm. The results presented shows that only 0.03% of the words contained in the dataset were corrected in comparison with the rule-based algorithm performance. The proposed model, then, achieved a WER of 0.45 ± 0.13%. This result indicate that the model has the ability to detect the stress patterns of the BP language.

As a general conclusion for the analysis, I have researched the performance of data-driven solutions and shown able to achieve state-of-the-art results on the Natural Language Processing algorithms presented in a Brazilian Portuguese Text-to-Speech system. More information about this problem can be seen in my Master’s thesis. Nowadays, however, there are models much more powerful and complex than simple Sequence-to-Sequence models and better results can be achieved. The power and flexibility of these models open the doors to different applications that will be in our daily life in the near future.